Your user tells the agent something important. Three days later, it’s gone.
The agent from last week has no memory of who they are, what was said, or what worked. Every session resets. If your users have complained that your AI feature “feels dumb” or “keeps forgetting things,” the culprit is usually the same: a product decision that nobody made.
That decision is about memory architecture.
A language model, on its own, is stateless. Every time you send it a message, it starts from scratch. There’s no persistent storage inside the model and no “previous conversation” living in the weights.
An agent carries information forward through the system wrapped around it. That system, the orchestration layer, is what “agent memory” actually refers to. The model stays stateless; what persists is handled by the architecture around it.
For PMs, this is the key reframe: building an agent feature means defining what the system around the model remembers, how it decides what to keep, and what happens when the information it stored turns out to be wrong. The decisions belong to product even when engineering is the one implementing them. In most teams, nobody actually says that out loud.

Thanks for reading!
Subscribe to The Product Foundry by Doug Seven to get articles like this in your inbox.
Subscribe on Substack →Four Types, Four Decisions
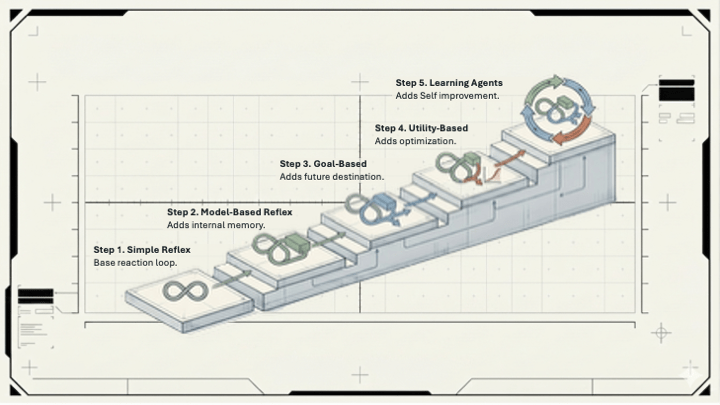
There are four types of memory that can exist in an agent system. Each one forces a different product call.
Working memory is the active scratchpad. Everything currently in the context window: the conversation so far, the task the agent is running, any information it just retrieved. Working memory is fast and accurate, but it has a hard ceiling. Every model has a maximum context window, and once your conversation outgrows it, something has to get dropped. Who decides what gets dropped? That’s a product decision with real user consequences, and in most systems right now, the answer is “whatever the default library behavior does.”
Episodic memory is the record of what happened, when. “Remember that project you mentioned last week?” works because of episodic memory. Without it, your agent resets with every session, can’t build on previous decisions, and can’t behave like it knows the user. If your agent is supposed to feel like a knowledgeable colleague rather than a first-day hire, episodic memory is what makes that possible.
Semantic memory is the knowledge base the agent can pull from: product documentation, company policies, user preferences, domain facts. This one tends to get treated as a one-time setup problem (”we’ll load the docs in”), but the real questions are operational. What happens when the knowledge goes stale? Who maintains it? When two sources contradict each other, which one wins?
Consider an internal AI assistant trained on a company’s HR policy documents. Open enrollment rules change in October. Updating the knowledge base gets deprioritized. It sits in the gray zone between product and IT, and gray zones rarely get done. For three months, the agent confidently tells employees about last year’s plan options. Support tickets spike. The agent wasn’t wrong when it was built. Nobody owned keeping it current.
Procedural memory is the agent’s toolkit: the tools it knows how to call, the patterns it applies to certain types of tasks. This one often lives below the product conversation entirely, until something it “knows how to do” breaks or produces the wrong output at an edge case that matters.
Once you’ve decided which types to implement, the harder question is how to manage them over time and what happens when they conflict.
Write, Update, Supersede, Redact, Forget
In a production agent, memory is a lifecycle.

Here’s a concrete version of what goes wrong. A user tells your agent “I moved from Chicago to Austin last month.” A naive implementation overwrites the old city. Fine. But now the system can’t answer “where did this user used to live?” And if location was informing recommendations, the transition period produces wrong suggestions while the system catches up. A governed implementation marks the old fact as superseded rather than deleting it, timestamps both entries, and knows which to surface depending on what’s being asked.
This is a user trust problem, not just an engineering edge case. If your agent says “based on your preferences in Chicago…” six weeks after the user moved, the user doesn’t think “there’s a temporal metadata problem.” They think the product is broken.
The harder version involves multi-agent systems. Once you have more than one agent working together on a workflow, memory becomes a permissions problem: which agent owns which memories, what gets shared, and what stays private. The real failure mode is agents sharing the wrong memory with the wrong agent, and that reaching the wrong user. The right default is private memory unless there’s an explicit reason to share. In most systems where nobody made that call, the default is the opposite.
Five Questions to Ask Before You Ship
If you’re working on an agent feature right now, these are worth bringing to your engineering team. Not because you need to understand the implementation, but because the answers reveal whether these decisions were made at all.
What type of memory does this agent actually use? If the answer is “context window plus a vector database,” ask what happens when the context window fills. Something gets dropped. What is it?
When a user provides information that contradicts what’s already stored, how does the system handle it? Does it update, append, or ignore? Is that a deliberate product decision, or the default behavior of whatever library was used?
If this agent shares a workflow with other agents, which memory is private and which is shared? Push for an explicit policy. “We’ll figure it out” is how cross-user data leakage happens.
Has anyone defined what happens when a user asks to be forgotten? This is a trust and regulatory question as much as a technical one, and the answer needs to be a documented policy. The engineers will implement whatever you specify; if nobody specifies anything, they’ll pick the simplest default. (That default is almost never the right one.)
How does the agent handle facts that age? If the agent treats everything it ever stored as equally current, it will eventually be confidently wrong about something that matters.
None of these require you to understand vector databases or embedding models. They require someone to have thought through the user experience at the edges.
The Version That Doesn’t Embarrass You in Production
Memory architecture is to agents what data modeling is to databases. It’s rarely what excites anyone in the planning phase, but it’s what determines whether the system is actually trustworthy at scale, or whether it surprises you in ways you’ll be explaining to customers for weeks.
Work through these questions before launch. Discovering memory governance failures in production means retrofitting a layer that should have been there from the start, and doing that on a live system is as painful as it sounds.
This is a product decision. Treat it like one.






Leave a comment