You’re three sections into an AI feature spec. You have the user story, the success metrics, a few edge cases. Then one question stops you: what does the agent do when it hasn’t seen this before? Or: should it remember what this user told it last week? Or: when there are two valid paths, how does it decide?
You’re not sure if those questions belong in your spec or in the engineering design doc. So you move on and hope someone downstream figures it out.
Here’s what’s happening when that moment arrives: you’ve just hit the architectural question…the one that determines what kind of agent you’re actually building. Most teams skip it entirely and let it get answered by library or framework defaults. What follows isn’t an AI failure. It’s a product definition gap.
Understanding agent architectures isn’t an academic exercise. It’s the part of AI PM’s work.
Thanks for reading The Product Foundry! Subscribe for free to receive new posts and support this community.
The 5 Types of Intelligent Agents (Yes, From a Textbook)
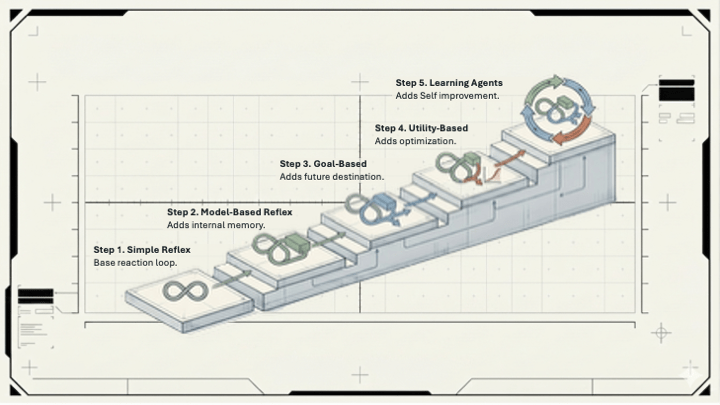
Stuart Russell and Peter Norvig defined an agent simply: something that perceives its environment and takes actions to achieve a goal. Their book, Artificial Intelligence: A Modern Approach, first published in 1995, with the full five-type taxonomy arriving in the 2003 second edition, laid out five increasingly capable architectures.
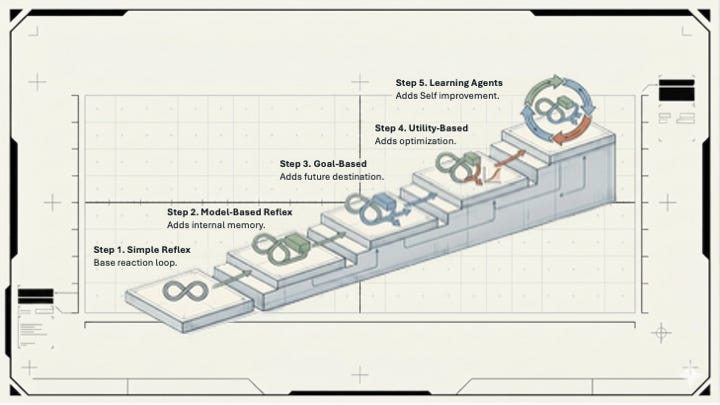
These aren’t historical artifacts. They describe almost exactly what’s inside Claude, Gemini, and every enterprise AI platform being pitched to your company right now. The taxonomy is old because the underlying problem is old: how does an agent act sensibly in a world it doesn’t fully understand?
An agent is anything that can be viewed as perceiving its environment through sensors and acting upon that environment through effectors. A human agent has eyes, ears, and other organs for sensors, and hands, legs, mouth, and other body parts for effectors. A robotic agent substitutes cameras and infrared range finders for the sensors and various motors for the effectors. A software agent has encoded bit strings as its percepts and actions.
Artificial Intelligence: A Modern Approach, Second Edition
Stuart J. Russell and Peter Norvig
Simple reflex agents operate on if-then logic and nothing else. If the input matches a rule, the agent fires the rule. No history, no prediction, no judgment. Content moderation filters are a good example: if a message contains X, remove it. Fast, consistent, and completely blind to anything outside the lookup table. When we originally built Amazon CodeWhisperer, this is (simplified) how we filtered out copyrighted material – a look up table and if-then logic.
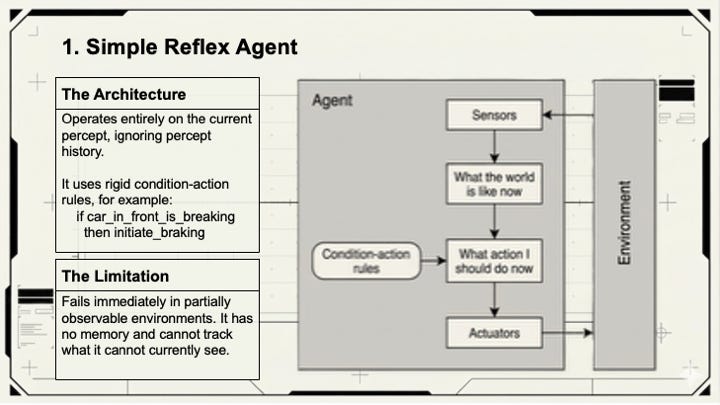
Model-based reflex agents add memory. They maintain an internal state that tracks parts of the world they can’t currently observe, then use that model to make better decisions. The context window in Claude or Gemini is exactly this: a running record of the conversation that lets the agent reason about what was said three messages ago even when it can’t directly reference it.
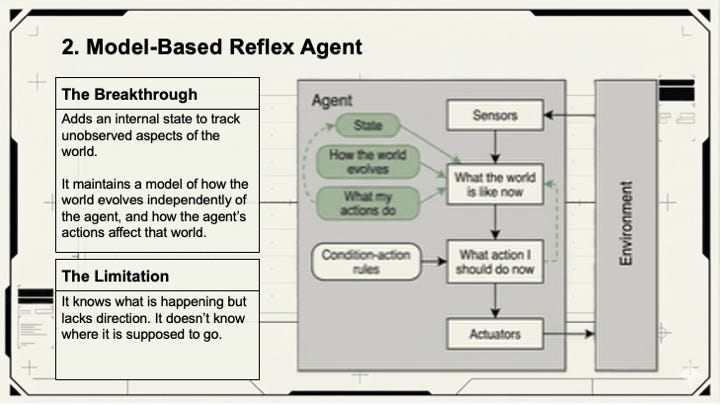
Goal-based agents add intentionality. Instead of reacting to inputs, they reason forward toward a desired state. When you hand Claude a complex task such as “Find a meeting time that works for all five attendees, avoids my blocked focus hours, and leaves a 30-minute buffer before the board call” it’s operating as a goal-based agent. The prompt is goal information. The output is the plan for reaching it.
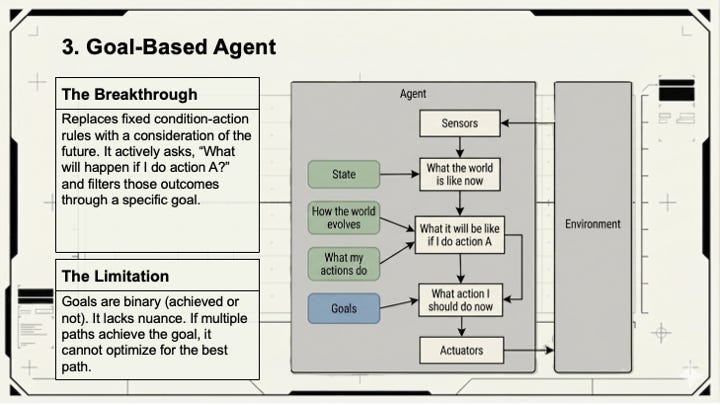
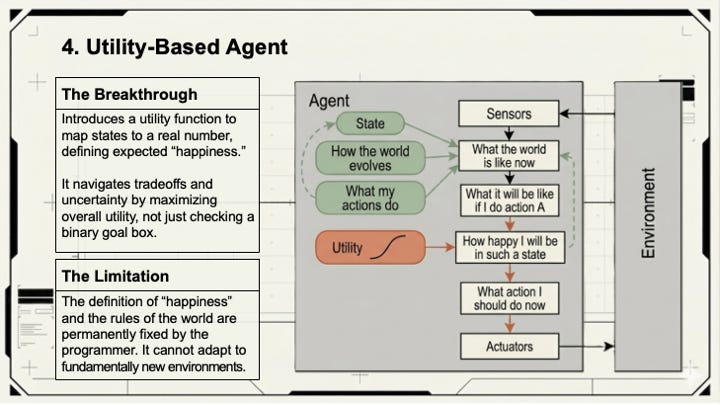
Utility-based agents handle trade-offs. When multiple paths lead to the goal, which one is best? These agents evaluate options by expected utility: the probability of a good outcome multiplied by how good that outcome actually is. An agent choosing between a faster-but-riskier approach and a slower-but-safer one needs a utility function to make that call rationally. Without one, it guesses.
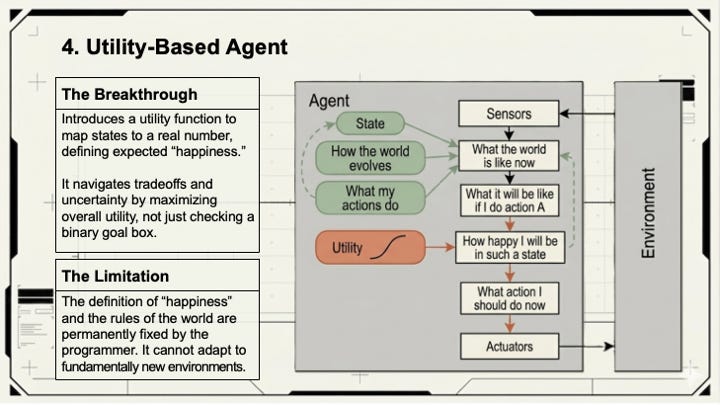
Learning agents close the loop. They observe their own performance, compare it against a standard, and modify behavior accordingly. The large language models underneath Claude and Gemini are learning agents at their foundation; their capability came from observing billions of examples and adjusting internal parameters based on feedback, not from hand-coded rules.
What Claude and Gemini Actually Are
Neither Claude nor Gemini is a single agent type. They’re hybrids, running multiple modes simultaneously. To understand which layer is active at any moment, it helps to understand how these systems were built.
Start with learning agents, because that’s the foundation. A simple reflex agent is hard-coded: its behaviors were written by a programmer and stay fixed. Claude and Gemini developed their competence the other way. By observing enormous amounts of human-generated text and adjusting internal parameters based on feedback.
Russell and Norvig’s learning agent has four components. Each one maps cleanly onto how RLHF (Reinforcement Learning from Human Feedback) works:
The performance element is the model itself. It is the part that takes a prompt (the percept, what the agent perceives from its environment) and generates a response (the action).
The critic evaluates how well the performance element is doing against a standard. In modern AI training, the critic isn’t just an algorithm. It’s human evaluators grading responses for helpfulness, accuracy, and safety. That’s a meaningful distinction from traditional reinforcement learning: the performance standard is human judgment, not a fixed scoring function. This is why these models reflect something that looks like values rather than just pattern-matching.
The learning element takes the critic’s feedback and adjusts the model’s weights so future responses more closely match what the critic rewarded. The learning element has been steering the model toward patterns that humans found useful, across billions of examples.
The problem generator encourages the model to try responses and reasoning paths it hasn’t explored before. Without it, the model would converge on safe, mediocre outputs. Always ordering the same thing because you know it’s fine. The problem generator is what makes these systems capable of surprising you with an approach you didn’t anticipate.
Understanding the learning agent structure matters practically because it explains the gap between “generally capable” and “reliably useful for this specific task.” The model was trained to be helpful and safe in the broad sense. It wasn’t trained for your task environment. That gap is what fine-tuning, system prompts, and product design are supposed to close. If your spec doesn’t address it, nobody else will.
The chat interface operates as a model-based reflex agent. The context window is the internal state (i.e., the model’s working model of the conversation). Every new message gets processed in the context of what came before, including exchanges from earlier that aren’t being directly referenced. That history is the world the agent is tracking. When a long conversation suddenly loses its thread, or the model contradicts something it agreed to earlier, you’ve hit a state management problem. Information was dropped from the internal model, and nobody decided what would go.
When you hand the model a specific task, it shifts into goal-based mode. The prompt is goal information (i.e., a description of the desired state). The model reasons through possible paths to find the sequence most likely to reach it.
The safety filters are simple reflex agents. Certain inputs trigger certain outputs without contextual reasoning. When you’ve gotten a refusal that clearly doesn’t fit the actual request, such as one that any human would read as a misfire, you’ve hit the seam between the goal-based reasoning layer and the condition-action reflex layer underneath it. The model didn’t think its way to that refusal. It matched a pattern and fired a rule.
Knowing which layer is active changes what kind of problem you have and where the fix lives: in the prompt, in the architecture, or in the product definition.
Agents That Don’t Wait to Be Asked
Most of what I’ve described lives inside a chat box. The more significant shift for enterprise PMs is what happens when it doesn’t.
A situated agent is embedded in a real environment rather than sandboxed in a text interface. It has continuous access to inputs from the world around it: emails arriving, calendar events changing, a price moving in a system it’s monitoring. It doesn’t wait for a prompt. It watches.
This changes the design problem fundamentally. A conversational AI feature takes an input and returns a response. A situated agent takes a goal and operates until it’s achieved, or until something in the environment changes that requires it to replan.
Sensors and actuators are the practical vocabulary for this. In a platform like Google Workspace with Gemini embedded, the sensors are the emails, calendar events, and documents the agent can read. The actuators are what it can write, schedule, or trigger. Success is no longer a good text response. It’s a change in the state of the world.
The continuous planning agent is qualitatively different from a prompt-response system. It doesn’t answer a question and stop. It monitors, updates its model of the world when something changes, a dependency unblocks, a stakeholder replies, a deadline shifts, and replans accordingly. The agent has a lifetime, not a session.
This is where utility-based architecture becomes non-optional. An enterprise agent operating autonomously faces constant trade-offs. Complete a task quickly using an expensive model, or take longer with a cheaper one? Handle an ambiguous edge case independently, or escalate to a human? Each of those decisions requires a utility function (i.e., a definition of what “good” means when outcomes are uncertain and resources are constrained).
That definition is a product decision. The PM who doesn’t write it is leaving it to whoever set the library defaults.
Designing Systems, Not Tools
An autonomous agent operating inside a defined task environment is one problem. Multiple autonomous agents sharing an environment is a different one entirely, and where most enterprise AI roadmaps are quietly headed.
Multiagent systems (MAS) have been studied theoretically for decades. They’re now showing up in production software. A contract workflow might run a drafting agent, a legal review agent, a pricing agent, and an approval-routing agent, all handling different parts of the same process, sometimes simultaneously. Each one is operating rationally toward its own goal.
When agents share an environment, they need coordination. Two agents working toward compatible goals can collaborate. Two agents working toward conflicting ones can deadlock, produce contradictory outputs, or both “succeed” at something that makes no sense together.
The coordination mechanisms come in two flavors. Conventions are pre-agreed rules: if a contract is flagged as high-risk, the legal agent owns it. No negotiation, no ambiguity. Explicit communication protocols are more flexible: agents can surface conflicts, request handoffs, and negotiate. More powerful, more complex, and much harder to debug when something goes wrong.
Claude and Gemini are already acting as multiagent coordinators in their more capable configurations, such as Gemini Enterprise and the Google Agent Platform, receiving a complex goal, breaking it into subtasks, calling other services or agents, and assembling the results. The PM designing a workflow on top of these platforms isn’t designing a tool. They’re designing a system of interacting agents, each with its own goals, constraints, and failure modes. That’s a different kind of spec than most teams have written before.
The PEAS Framework: Your New Starting Point
Most AI feature specs today start with the persona. How should the agent sound? What tone? What name? I have written about this before in Agentic AI 101 for Product Managers. The persona is important, but it is the wrong first question. The persona is styling. The architecture is the product.
The PEAS framework (Performance, Environment, Actuators, Sensors) gives you a structured way to define a task environment before deciding anything about implementation. It comes from the same Russell and Norvig textbook as the five agent types.
Performance: What does success look like, measured specifically? Not “the agent is helpful,” something measurable: “90% of tier-1 support tickets resolved without escalation, average handle time under 3 minutes.” The performance measure is what the agent optimizes for, consciously or not. Define it vaguely and you get a vague agent.
Environment: Where does the agent operate, and what are the properties of that environment? Is it fully observable, meaning the agent can see everything relevant, or partially observable, meaning it has to infer things it can’t directly see? Is it static or dynamic? A customer support agent working in live chat, with a knowledge base last updated six months ago, is operating in a partially observable, dynamic environment. Your spec should say that, because it shapes every decision the agent makes under uncertainty.
Actuators: What can the agent do? List every action explicitly. Write a response. Create a calendar event. Escalate to a human. Submit a ticket. The boundary of the actuator list is the boundary of the agent’s capability. If an action isn’t on the list, the agent shouldn’t be doing it. If it does, that’s not a model problem. It’s a product definition problem. For example, when we were building Amazon CodeWhisperer, we explicitly stated that political, financial, and religious prompts would not be answered (among others). That was not the scope for a coding assistant.
Sensors: What can the agent perceive? User messages, previous conversation history, JSON from an API call, records from a database, the current timestamp. The sensor list tells you what information is available when the agent makes decisions. If a decision requires information that isn’t on the sensor list, the agent is going to guess. Sometimes it’ll guess well. More often it won’t, and you’ll spend three sprints trying to figure out why.
Starting a spec with PEAS instead of a persona shifts the conversation from “how should this agent sound?” to “what can this agent do, see, and be held accountable for?” That shift catches structural gaps before they become bugs.
From Feature Spec to Task Environment
The PM role in AI product development is shifting faster than the job description. The practical version of that shift isn’t adding “AI” to your title or becoming a prompt engineer. It’s taking ownership of decisions that used to get made implicitly, by engineers, by framework defaults, or by nobody at all.
Russell and Norvig called the broader version of this ontological engineering: defining the categories, rules, and goals of the world the agent operates in. It means deciding what counts as success, what the agent is and isn’t permitted to do, how it should behave when it encounters something outside its design, and what happens when its goals conflict with another agent’s.
Those have always been product decisions. The difference is that until recently, there was usually a human in the loop to exercise judgment when the spec ran out. Agents don’t pause to ask.
Start your next PRD by defining your agent’s PEAS, not its persona. The persona is easy. The task environment is where the product actually lives.






Leave a comment